 当前位置:
当前位置:服务热线
0755-83647532

发表日期:2018-01-30 文章编辑:管理员 阅读次数:
作者:高明星 胡明月 金运通
本系列将分三部分,第一部分介绍项目概述和“控制平面性能测试及优化
一、项目简介
铁路作为一种大众化的交通工具和非常重要的货物运输方式,其业务规模庞大、覆盖全国、服务全国各族人民。面对时代的变革和向现代物流企业转型的需要,铁路IT部门需要建设更高效灵活、部署简便、安全可控的IT基础设施。为了更好地支持中国铁路总公司从传统客货运输企业向现代物流企业转型,中国铁路信息技术中心于2014年底决定研发云计算解决方案和产品,由此“铁信云”应运而生。
为了更好地支持中国铁路总公司从传统客货运输企业向现代物流企业转型,中国铁路信息技术中心于2014年底决定研发云计算解决方案和产品。作为一个大型行业的OpenStack用户,中国铁路总公司希望真正掌握开源技术,安全可控地运用在生产中,而不是简单的产品使用方,同时为了打造用户与厂商共生互利的OpenStack新商业生态,“铁信云”产品采用了业界创新的联合研发模式,由中国铁路信息技术中心牵头组织,北京中铁信科技有限公司和北京云途腾科技有限责任公司一起联合研制。
基于铁路的应用及运维特点,铁信云要求以“稳定性、可靠性、易用性、安全性”为标准对OpenStack进行二次开发,解决OpenStack开源架构下各种模块与组件的不足,同时为了满足铁路行业超大规模行业云部署实施,并对业务应用提供高性能、稳定可靠的支撑,Intel联合各方一起做了一系列的测试调优和验证工作,主要分为以下3个部分:
控制平面性能测试及优化
通过测试来验证铁信云在单一region下能支撑的最大规模,寻找在单一region下部署的高效优化架构设计方案,以及在该架构下的优化参数配置,以保障其在超大规模部署和高负载条件下云服务能高效、稳定、可靠运行。
数据平面性能测试及优化
云平台承载业务的性能及运行稳定性与云平台的数据平面密切相关,通过对存储,计算,网络方面的性能测试和优化来验证Intel产品及技术对云平台数据平面的性能支撑,并为生产环境的部署及配置提供参考和优化方法。
关键应用负载Oracle RAC性能测试及优化
Oracle RAC数据库作为铁路信息系统中的关键应用,在控制平面及数据平面的优化验证基础之上,我们对Oracle RAC在铁信云环境中进行了部署和验证。
二、铁信云架构介绍
“铁信云”云平台目前主要包括基础设施服务层(IaaS)和平台服务层(PaaS),整体架构如下图所示:
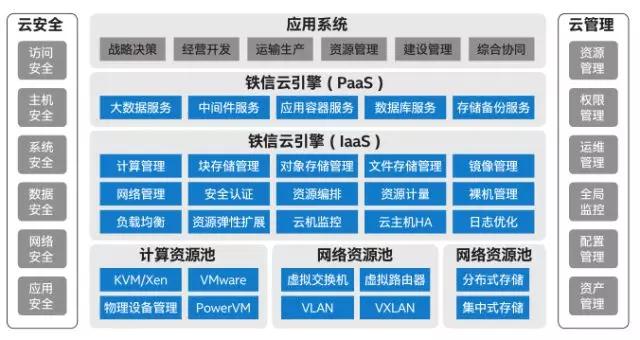
“铁信云”的基础设施服务层(IaaS),以OpenStack架构为基础,实现对计算资源池、存储资源池和网络资源池进行统一管理和调度,为信息系统应用部署提供基础资源服务。计算资源池支持对KVM、VMware、X86裸机、Power设备等多种资源的统一管理;存储资源池支持对基于X86服务器的分布式存储和基于传统商用存储等多种资源的统一管理;网络资源池支持对VLAN、VxLAN等多种模式下的物理和虚拟网络资源的统一管理。
“铁信云”的平台服务层(PaaS),为应用运行提供数据库、中间件、大数据、数据备份等平台软件的统一部署服务;提供数据抽取、分析、存储及展示等服务,同时基于容器技术提供应用快速部署及迁移服务。
“铁信云”还根据大规模部署等需求,不断改进完善云平台功能。例如改进了云主机监控方式,舍弃了Ceilometer的监控功能,集成了Open-Falcon;增加了日志审计模块,便于管理员和租户查阅操作日志;实现了云主机HA,支持物理主机故障时云主机自动迁移,等等。
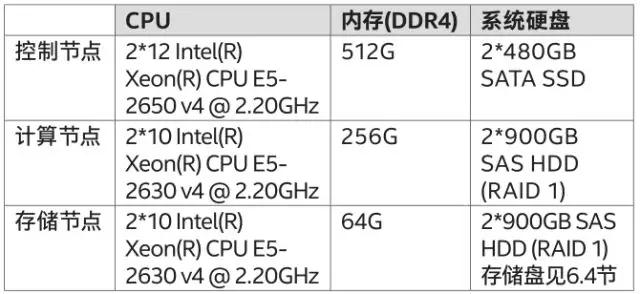
“铁信云”一期项目大规模部署环境中包括一个由780个物理节点构成的云系统,其中有3个控制节点、600个主机作为计算节点,网络节点在计算节点上、117个存储节点等。
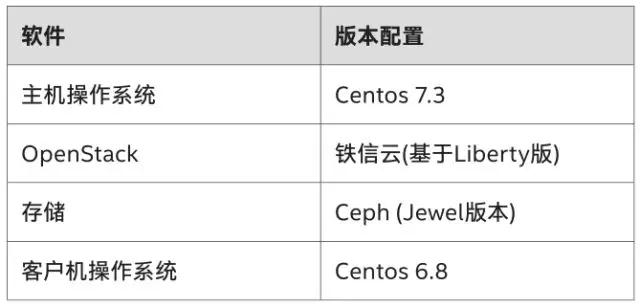
本次大规模优化验证基于以上铁信云780个节点的系统,主要软硬件设备及基本配置如下表所示:
三、控制平面性能测试及优化
控制平面是指在云环境下为实现IT资源的统一管理和调度而设备互联形成的网络,设备包括控制节点和被管控的计算、存储、网络等资源节点;建立控制平面的目的是通过充分利用IT资源以更好地满足业务应用运行需求。
控制平面的性能是云平台大规模部署的基础和关键,大规模行业云的控制平面部署设计有多种方案,如单一region规模化部署、多region部署、多cell等模式,无论哪种模式,单一region下的规模部署是基础。通过测试来验证铁信云在单一region下能支撑的最大规模,试图寻找在单一region下部署的高效优化架构设计方案,以及在该架构下的优化参数配置,以保障其在超大规模部署和高负载条件下云服务能高效、稳定、可靠运行。
3.1 控制平面测试介绍
3.1.1 测试目的及方法
此次案例以探索单region的规模和性能边界为目标做了测试和优化,最终希望利用现有经验探索大规模数据中心的云平台部署最佳实践:
• 观察一定规模计算节点下创建云主机压力对控制节点集群的影响,例如CPU、内存、网络IO、磁盘IO等,为今后大规模云数据中心的云平台设计、扩容提供数据基础。
• 并发及资源利用率考量。来自用户的并发请求对整体系统稳定性的考量,即寻找数据库、RabbitMQ集群和OpenStack组件瓶颈,期望通过改良系统参数、服务配置、代码逻辑,在服务稳定的前提下最大化提高物理资源的使用效率。
我们依次对100、200、300、400、500、600物理计算节点做了多轮测试及优化:
• 通过固定计算节点数,以1:20的比例(1台计算节点创建20台云主机)分批次创建相应数量的云主机,通过查询数据库和日志信息可以计算获得其创建成功率,通过分析日志,对每台创建成功的云主机,都可以计算得到它在创建过程中各模块的时间消耗,并以此衡量创建云主机的性能。
• 针对RabbitMQ的分析,基于一组以1:2的比例(1台计算节点创建2台云主机)分批次创建云主机的场景,用以获取准确的实际消息数目,建立基准模型供后续分析参考验证。基于此,利用监控数据定性分析在1:20比例下的优化效果。
• 模拟多API同时触发,针对失败的请求,结合系统返回的信息和日志观察,分析错误原因。
• 通过用一些性能监测工具对创建云主机过程进行性能评测。
3.2 控制平面性能测试分析及优化
先对社区默认的参数配置进行测试,通过对日志数据的收集和分析发现大规模部署中的瓶颈所在,并逐步加以优化和验证,最终得出大规模部署下最佳配置和部署实践。
3.2.1 第一轮参数优化调
社区默认配置无法直接承载600+计算节点规模,表征如下:
• RabbitMQ连接超时,如图4-1和4-2所示
• 无法执行创建、获取资源等任务
• Keystone无法响应等
第一轮参数优化调整的目标是为了满足大规模节点部署的应用场景,使云管理平台能够基本正常运行。如下表所示,我们对系统参数、数据库配置、OpenStack组件分别根据需求做了调整。
例如,操作系统方面,我们调整了最大文件描述符、最大线程数,以提高单个系统吞吐能力;数据库方面,我们调整了openfile限制,调大了查询缓存,以提高数据库节点的整体性能;OpenStack方面,我们根据自身环境情况做了RPC相关的服务配置,以缓解服务端压力。
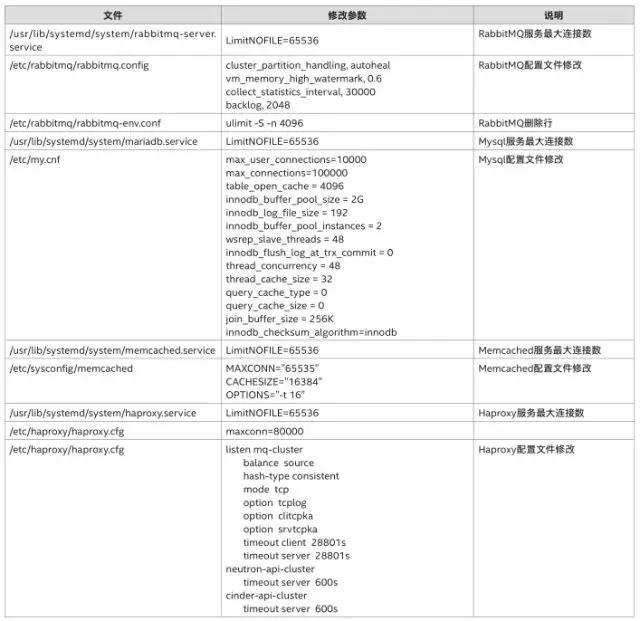

经过上述第一轮参数配置修改后,600+节点构成的云平台工作正常,并能正常对外提供服务。
3.2.2 第二轮参数优化调整
第二轮参数优化调整的目标是为了进一步提高云平台运行的稳定性和可靠性。经过上述第一轮参数调整,在高并发和高负载条件下创建云主机,仍然还存在较高的失败率。为更好地了解创建云主机流程和错误性质,我们分析了3组场景(200、400、600计算节点,以1:20比例创建云主机)的详细日志以及数据库中的所有相关信息。在全部24000个请求中,我们成功追踪到所有请求,其中17703个请求成功完成,成功率仅为73.76%。
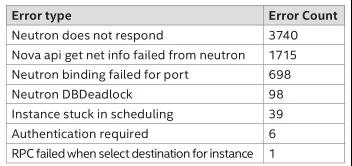
我们对创建过程中的错误进行了分类,下表展示了错误分布情况。基于分词、特征提取以及聚类建模分析,我们得到关键错误信息,消除了重复和不相关的信息.
3.2.2.1两大错误问题分析
列出了的几种错误表现形式,可以主要归纳为以下两大错误类型:
• 消息队列相关问题:在压力太大的情况下,RabbitMQ集群不稳定因素会导致队列同步失败,最终消息丢失, 或者直接导致队列消失,消费者无法拿到消息等。因此出现,Neutron linuxbridge agent上报状态失败,neutron-server误认为与port绑定的linuxbridge agent处于dead状态,导致port绑定失败;Nova通过RPC与nova-scheduler交互选择host主机失败导致选择主机失败、与nova-compute交互执行创建云主机操作失败导致云主机一直处于scheduling状态等情况。
• 数据库问题:一方面,数据库表死锁,主要集中在Neutron创建port分配IP的过程中,并发分配网络IP时会导致资源争抢;另一方面,在nova-compute准备网络资源、及nova-api检验请求网络信息时与Neutron交互的过程中,由于数据库读写较慢导致Neutron处理请求过慢,无法响应Nova的请求。
3.2.2.2参数再次优化调整
经进一步调查研究发现,表4-2列出的异常及错误问题,可采用如下方法规避并进一步调优。
• 适 当增 加 N e u t r o n 配 置中的 a ge nt _ d ow n _ t i m e,避 免linuxbridge agent出现僵死的现象。适当增加Nova配置文件的the service_down_time,避免novascheduler调度过程中出现nova-compute僵死的现象。
• 将Nova配置文件中的the rpc_response_timeout设置为更长的时间,允许更长的时间等待nova-scheduler调度。
经过上述参数优化调整后,可以在一定程度上缓解创建云主机的失败率。完成第二轮参数优化调整后,我们再次在相同的3个场景下,共创建24000台云主机,成功率由73.76%上升至84.50%。但是仍然有一部分错误需要解决,接下来我们对2大错误问题根源入手进行更深层次的分析优化。
3.2.3消息统计模型及消息通信架构调整
测试过程中,伴随集群规模扩大(主要是计算节点增加),服务端对成功响应创建请求的占比有所下降。通过进一步对错误日志分析,在创建过程中,通常会出现以下几类异常:
• 消息队列丢失导致云主机一直处于调度状态(已经选出主机,但是计算节点没有处理相关任务,云主机状态也不会变成error)
• 各服务连接RabbitMQ失败并不断重连
• 处理创建请求的过程中RabbitMQ崩溃针对消息队列压力过大的问题,我们对比配置了nova-conductor的两种API模式,由rpc改为local模式;另一方面,notification driver配置为noop。
这些措施一定程度上减少了消息队列的负荷。同时,我们结合源码对测试数据进行分析,先从源码中汇总创建过程中出现的rpc方法,再根据涉及的rpc类型估计相应的消息数目,最后得到关于创建请求产生的消息总数的计算模型,通过分析测试过程中RabbitMQ产生的的trace日志,可以获取实际消息数目。但考虑到大规模创建对RabbitMQ的压力,我们采取的是小规模(按照1:2的比例为每个计算节点创建云主机)定量验证模型,大规模定性分析优化结果的方法。在小规模环境下,经过对比,实际消息数与我们的模型分析结果一致。
结果表明,消息总数和计算节点数紧密相关,会随着计算节点规模的增加而迅速增加,分析发现主要消息来源是neutron-server向linuxbridge agent发送l2 population和安全组信息的广播涉及的两个方法:securitygroups_member_updated和add_fdb_entries。例如600个节点会产生千万级别 [注1] 的消息经由消息队列处理, 而l2 population和安全组的消息占这个消息总数的90%以上。因此我们将这两类消息进行了剥离,以减轻RabbitMQ的负担.
通过分析OpenStack服务的行为,我们可以成功评估所需消息队列节点的规模,并对未来集群规模做科学的制定和规划。
3.2.4 OpenStack组件数据库负载分析及优化
前文描述过,在并发创建的时候,由于neutron在分配IP地址时,会发生严重的资源争抢,这在高并发下会导致请求缓慢,甚至请求超时的错误发生。通过仔细分析,这是由于在liberty版本中,IP地址的分配是通过select…for update语句触发,该类语句会在数据库层获取相关行的intend lock,高并发情况下,同一子网内的IP分配请求都会对该子网所对应的数据库表的intend lock进行争抢。
从而导致资源忙等待超时,在业务层面就会表现出数据库 deadlock。虽然在业务层面对该类异常进行了重试,但在实际的测试中发现分配成功率并没有得到太大的改善。
而在mitaka版本之后, IP分配方式得以改进。更改后的逻辑不再使用select…for update的方式获得结果,而是组合了select语句配合一个窗口值随机分配IP地址。因为相关的IP分配流程都在内存中进行,这就避免了IPAvailabilityRanges表加锁,我们更新(backport)了相关patch,图4-6中对比了修改IP分配逻辑前后的rally测试结果。两张结果对比了更新patch前后并发创建port时的成功率及耗时。可以看到社区的patch修复效果较为明显,并发创建240个port成功率和耗时上都较修复前有了较大的改进。
在测试过程中,我们也尝试通过其他的架构来提高数据库的并发事务能力,我们通过在数据库系统中开启dtrace探针来分析云主机生成期间数据库的访问行为,例如分析OpenStack不同项目数据库的访问热度、CUID(create,update,insert,delete)执行比例及耗时等。
发现在云主机并发创建期间,OpenStack不同项目的CUID占比。我们可以看到neutron, nova SELECT读的占比分别达到82.1%(1972/2400)和62.1%(2356/3790)
因此,当数据库集群主节点负荷较高时,我们可以通过在数据库集群和sqlachemy之间增加数据库代理来分发读写请求。当然,这首先需要在业务层增加额外的代码来帮助数据库代理层识别读事务与写事务请求,数据库代理会透明的将读事务和写事务分发到不同的数据库实例上,这可以有效的提高数据库的并发事务能力。
3.2.5综合优化前后云主机创建请求成功率及耗时分析
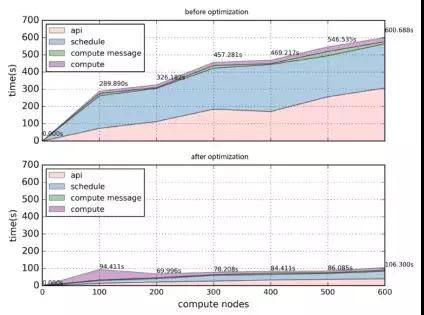
经过部分参数调优后,集群规模从100依次增长到600个节点时,由于数据库、RabbitMQ、OpenStack组件服务的原因创建云主机的成功率从100%逐渐衰减到80%。描述nova-api、nova-scheduler、控制节点nova服务向计算节点发送RPC消息、nova-compute这四部分组件级别耗时)对比了相同规模相同压力下,RabbitMQ和数据库进一步调优前后,按照每个计算点20台云主机的比例创建云主机过程的平均耗时。可以看到,随着集群规模增加,创建耗时逐渐增长,当集群规模增长到600个节点时,单台云主机创建平均耗时可达到600s左右。在前面的基础上,通过对大量日志及相关监控数据的进一步分析,我们发现nova-api等待neutron-server返回网络信息时间较长,导致novaapi耗时较长,同时,nova-scheduler处理时间也较长,根源还是在于数据库和RabbitMQ的性能限制了云平台处理请求的能力。
经过RabbitMQ和数据库进行进一步调整优化后,nova-scheduler调度效率提高了20倍, neutron-server的吞吐提高了90%。优化后,并发创建云主机的成功率几乎不受集群规模的影响,没有明显波动,稳定在100%附近;平均创建时间也比优化前也有明显缩短。
文章摘自英特尔精英汇
CA88集团联系方式
咨询热线:0755-88603572
CA88官网:www.clw500.com
客户垂询邮箱:cuifang.mo@clw500.com
客户垂询QQ:1627678462
地址:深圳市福田区深南大道1006号国际创新中心C座11楼
邮编:51802


 粤公网安备 44030402001885号
友情链接: 金沙古酒 | 中青宝 | 宝德控股 | 宝德计算 |
粤公网安备 44030402001885号
友情链接: 金沙古酒 | 中青宝 | 宝德控股 | 宝德计算 |